前言 前段时间出于对Lua底层机制与编译原理的学习,笔者尝试写了个简易的Lua解释器CatLua ,主要参考《自己动手实现Lua》(原书是Go语言实现,笔者选择了自己熟悉的C#语言,并且对原书很多地方的代码进行了符合自身审美的重构),其余则参考了《Lua设计与实现》、《Lua源码欣赏》
最终代码结构如下:
Chunk:包含保存读取到的Lua字节码信息的数据结构
Compiler:包含词法分析器(Lexer)、语法分析器(Parser)与函数原型编译器(Compiler)
Instruction:包含所有Lua虚拟机可执行的指令的定义与实现
LuaStack:包含用于Lua虚拟机进行数据操作、指令逻辑执行的Lua虚拟栈,以及Lua数据类型在C#层的对应实现
LuaState:包含核心Lua虚拟机,封装了大量对LuaStack的操作
Operator:包含运算符的定义与实现,包括数学运算、位运算、逻辑运算
StdLib:包含标准库的实现
Util:包含各类辅助代码
此文主要用于对CatLua的总结以及各部分实现思路的梳理,因此不会对每一处细节都进行讲解,若欲详细了解可自行到Github下载源码
Lua字节码读取 在借助Lua官方的编译器的情况下,可以先跳过比较麻烦的编译器实现,而直接从字节码读取开始
Chunk 一般而言,一个Lua文件就被视为一个Chunk(严格意义上来说,任何一段可被Lua解释器执行的代码就是一个Chunk)
Chunk定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 public class Chunk { public ChunkHeader Header; public byte UpvaluesSize; public FuncPrototype MainFunc; public static Chunk Undump (byte [] data { Chunk chunk = new Chunk(); ChunkReader reader = new ChunkReader(data); chunk.Header = reader.CheckHeader(); chunk.UpvaluesSize = reader.ReadByte(); chunk.MainFunc = reader.ReadProto(string .Empty); return chunk; } }
函数 Chunk被视为自动拥有一个主函数,而在其中定义的任何变量与函数都会被处理为这个主函数内部定义的变量与子函数,因此执行一段Chunk总是从该Chunk的主函数开始执行的,
这也就是为什么在Lua文件里不用定义“Main”函数,就可以直接执行里面的代码
函数定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 public class FuncPrototype { public string Source; public uint LineDefined; public uint LastLineDefined; public byte NumParams; public byte IsVararg; public byte MaxStackSize; public uint [] Code; public LuaConstantUnion[] Constants; public UpvalueInfo[] UpvalueInfos; public FuncPrototype[] Protos; public uint [] LineInfo; public LocalVarInfo[] Locvars; public string [] UpvalueNames; }
可以看出函数的本质就是一系列的“指令 ”,此外FuncPrototype还记录了与此函数相关的信息,如参数个数,局部变量信息等
指令 Lua是一种面向虚拟机的编程语言 (与此相对立的则是面向硬件的编程语言 ,如C/C++),依靠同一套指令集规范在不同实现的虚拟机上运行,达到跨平台与嵌入宿主语言作为脚本存在 的效果
Lua在5.0前是基于栈的虚拟机,而在5.0开始改为了基于寄存器的虚拟机,二者的主要区别在于:
基于栈的虚拟机只能使用push、pop来操作栈顶,因此需要的指令集较大,相同逻辑需要执行的指令较多,但是指令长度较短
基于寄存器的虚拟机可以直接对栈进行寻址(比如直接从栈底获取值,把栈顶倒数第n个值复制到栈顶等),所以需要的指令集较小,相同逻辑需要执行的指令较少,但由于需要把地址编码进指令中所以指令长度较长
一般而言,虚拟机在执行指令时,采用的都是将一个巨大的对指令的Switch Case包裹在循环中来不断执行指令,比如Lua官方C版虚拟机:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 void luaV_execute (lua_State *L) for (;;) { Instruction i; StkId ra; vmfetch(); vmdispatch (GET_OPCODE(i)) { vmcase(OP_MOVE) { setobjs2s(L, ra, RB(i)); vmbreak; } vmcase(OP_LOADK) { TValue *rb = k + GETARG_Bx(i); setobj2s(L, ra, rb); vmbreak; } vmcase(OP_LOADKX) { TValue *rb; lua_assert(GET_OPCODE(*ci->u.l.savedpc) == OP_EXTRAARG); rb = k + GETARG_Ax(*ci->u.l.savedpc++); setobj2s(L, ra, rb); vmbreak; } } } }
CatLua则是采用表驱动 的写法,将Lua指令与其相关参数及其对应实现逻辑封装为一个InstructionConfig类,并放入数组里,根据指令码ID进行索引(运算符实现也与此类似,后续便不重复了)
Instruction定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public class Instructoin { public Instructoin (uint code { this .code = code; } public void Execute (LuaState vm ) { Action<Instructoin, LuaState> function = InstructionConfig.Configs[OpCode].Func; if (function != null ) { function(this , vm); } else { throw new Exception("指令没有对应的函数实现:" + OpType.ToString()); } } }
InstructionConfig定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 public class InstructionConfig { public InstructionConfig (byte testFlag, byte setAFlag, OpArgType argBType, OpArgType argCType, OpMode opMode, OpCodeType type, Action<Instructoin, LuaState> func = null { TestFlag = testFlag; SetAFlag = setAFlag; ArgBType = argBType; ArgCType = argCType; OpMode = opMode; Type = type; Func = func; } public OpCodeType Type; public Action<Instructoin, LuaState> Func; public static InstructionConfig[] Configs = { new InstructionConfig(0 ,1 ,OpArgType.R,OpArgType.N,OpMode.IABC,OpCodeType.Move,InstructionFuncs.MoveFunc), new InstructionConfig(0 ,1 ,OpArgType.K,OpArgType.N,OpMode.IABx,OpCodeType.LoadK,InstructionFuncs.LoadKFunc), new InstructionConfig(0 ,1 ,OpArgType.N,OpArgType.N,OpMode.IABx,OpCodeType.LoadKX,InstructionFuncs.LoadKXFunc), new InstructionConfig(0 ,1 ,OpArgType.U,OpArgType.U,OpMode.IABC,OpCodeType.LoadBool,InstructionFuncs.LoadBoolFunc), }
这样对指令的执行就变成了在循环中查表
1 2 3 4 5 6 while (true ){ Instructoin i = new Instructoin(Fetch()); i.Execute(this ); }
优化建议 尽量用局部变量缓存全局变量,避免对全局变量的频繁使用
因为对全局变量的访问相比对局部变量的访问需要更多的指令
Lua数据类型 在整个虚拟机运行过程中,都是基于对Lua虚拟栈的操作来实现的,而栈中所保存的则是Lua内置的数据类型
Lua中有多种数据类型,如nil、布尔、数字、Table、函数等,这些数据类型在CatLua中都被统一封装为LuaDataUnion,其定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 public struct LuaDataUnion : IEqualityComparer<LuaDataUnion>{ public LuaDataType Type { get ; private set ; } public bool Boolean { get ; private set ; } public long Integer { get ; private set ; } public double Number { get ; private set ; } public string Str { get ; private set ; } public LuaTable Table { get ; private set ; } public Closure Closure { get ; private set ; } }
其中比较重要的有Table和Closure(闭包),接下来将着重讲解这两者
Table Table作为Lua中唯一的数据容器,可以说是十分万能的存在,其既能表现出数组的特性,又能表现出字典的特性,因此在CatLua中便直接使用了C#自带的数组和字典来实现Table,同时嵌套了一个Table来表示元表
LuaTable定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 public class LuaTable { public LuaTable (int arrSize = 0 ,int dictSize = 0 { arr = new List<LuaDataUnion>(arrSize); for (int i = 0 ; i < arrSize; i++) { arr.Add(default ); } dict = new Dictionary<LuaDataUnion, LuaDataUnion>(dictSize); } private List<LuaDataUnion> arr; private Dictionary<LuaDataUnion, LuaDataUnion> dict; public LuaTable MetaTable; }
元表与元方法 元表,即MetaTable ,在Lua中起到的作用相当于其他语言中运算符重载功能,通过设置与之对应的元方法,开发者可以自定义对Table的一些操作,比如赋值(Index)、取值(newindex)、调用(call)等
虚拟机会在执行相关操作时检测元表中是否有对应元方法,若有则进行元方法的调用,而不再继续进行原本的处理了
面向对象的实现 Lua OOP的实现思路有2种:
通过设置子类index元方法为其父类,使得在子类中查找不到的成员会上溯至父类查找
直接将父类成员深拷贝给子类
方法1在查找时需要一层层的网上找,有一定的性能损耗
方法2虽然查找快,但是在对象创建时会消耗更多内存
插入与扩容 CatLua在插入一个正整数key时,会先判断是否在数组长度内,若是,则放入数组中
否则继续检测是否只是刚好超出数组长度1位,若是,则放入数组触发扩容,扩容会导致将之前字典里存放的某些符合要求的正整数key的value值移动到数组部分
若上面的检测都不通过,则直接放入数组部分
详细源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 if (TryConvertToArrIndex(key, out long index) && index >= 1 ) { if (index <= arr.Count) { arr[(int )index - 1 ] = value ; if (index == arr.Count && value .Type == LuaDataType.Nil) { RemoveArrTailNil(); } return ; } if (index == arr.Count + 1 && value .Type != LuaDataType.Nil) { if (dict != null ) { dict.Remove(key); } arr.Add(value ); MoveDictToArr(); return ; } } if (value .Type != LuaDataType.Nil) { dict[key] = value ; } else { dict.Remove(key); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 private void MoveDictToArr ( { if (dict == null ) { return ; } int index = arr.Count + 1 ; while (true ) { LuaDataUnion key = Factory.NewInteger(index); if (dict.TryGetValue(key, out LuaDataUnion data)) { arr.Add(data); dict.Remove(key); index++; } else { break ; } } }
原版Lua虚拟机则是根据正整数Key是否落在当前数组可容纳范围内决定是否放入数组,并在hash部分满后进行rehash来对数组和hash表进行空间调整,最终目标是数组部分利用率超过50%
优化建议 长度小的table在新增元素时会触发多次rehash,在预先知道table元素数量时,应当进行预填充避免不必要的扩容与rehash操作
Closure(闭包)与Upvalue 闭包一般指的是使用了其外层函数局部变量的内部函数,而Upvalue则是这个被引用的局部变量
1 2 3 4 5 6 7 8 9 10 11 12 local func1 = function () local a = 1 local func2 = function () a = 2 end end
上面的func2就是一个闭包,而变量a就是一个Upvalue
闭包 闭包的定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 public class Closure { public Closure (FuncPrototype proto ) { Proto = proto; CSFunc = null ; if (Proto.UpvalueInfos.Length > 0 ) { Upvalues = new Upvalue[Proto.UpvalueInfos.Length]; } } public Closure (Func<LuaState, int , int > csFunc,int upvalueNum = 0 ) { Proto = null ; CSFunc = csFunc; if (upvalueNum > 0 ) { Upvalues = new Upvalue[upvalueNum]; } } public FuncPrototype Proto; public Func<LuaState, int ,int > CSFunc; public Upvalue[] Upvalues; }
可以看到闭包内部还被分为了两种:Lua函数闭包与C#函数闭包
因为在虚拟机实现上所有函数都是以闭包的形式存在的 (即便是Chunk主函数也捕获到了名为”_Env”的Upvalue),所以如果要在Lua代码中调用C#层定义的函数,就需要将其封装为可供虚拟机调用的函数形式 ,然后以闭包的方式传入
如print函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 private static int Print (LuaState vm, int argsNum ) { string s = string .Empty; s += "Lua Print:" ; LuaDataUnion[] datas = vm.PopN(argsNum); for (int i = 0 ; i < argsNum; i++) { s += datas[i].ToString(); s += '\t' ; } Debug.Log(s); return 0 ; }
C#闭包其固定参数为LuaState对象和参数数量 ,返回值则为该函数的返回值数量 ,如print函数无返回值则其C#闭包返回0
Upvalue 之所以会将被使用的局部变量称为Upvalue,是因为闭包会延长这个局部变量的生命周期,使其即便离开作用域仍然有可能存活
Upvalue的定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 public class Upvalue { public Upvalue (LuaDataUnion value ,bool isOpen = false ,int globalStackIndex = 0 ) { Value = value ; IsOpen = isOpen; GlobalStackIndex = globalStackIndex; } public bool IsOpen; public LuaDataUnion Value { get ; private set ; } public int GlobalStackIndex { get ; private set ; } public void SetValue (LuaDataUnion value ,LuaState vm ) { Value = value ; if (IsOpen) { vm.Push(Value); vm.PopAndCopy(GlobalStackIndex); } } }
在Lua中Upvalue是被区分为开放状态 与闭合状态 的
开放状态意味着此时此Upvalue所代表的局部变量仍然存活在栈中,修改Upvalue也需要修改栈中的局部变量
闭合状态意味着那个局部变量已经离开作用域了
在原版Lua的实现中,若Upvalue处于开放状态则使用指针v来引用那个局部变量,这样可以做到对Upvalue的修改会同时影响到栈中局部变量。而一旦闭合了,就将局部变量复制到value中并让v指向value,这样局部变量就成为了此Upvalue所独有
1 2 3 4 5 6 7 8 typedef struct UpVal { CommonHeader; TValue *v; union { TValue value; } u; } UpVal;
由于C#通常情况下没有指针,所以只能记录开放状态下的局部变量的栈中索引,然后在被修改时一并对栈中数据进行修改
Lua虚拟栈 有了对Lua数据类型的定义就可以着手于Lua虚拟栈了
其定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 public class LuaStack { public LuaStack (int size { stack = new LuaDataUnion[size]; Top = -1 ; } private LuaDataUnion[] stack; public int Top; public void Push (LuaDataUnion data ) { } public LuaDataUnion Pop ( { } public LuaDataUnion Get (int index { } public void Set (int index, LuaDataUnion value { } } }
Lua虚拟栈的本质就是使用LuaDataUnion数组来模拟栈,并记录栈顶位置,然后封装了对栈的基本操作
LuaState LuaState可理解为Lua虚拟机对象,其主要持有一个LuaStack作为全局虚拟栈,以及一个LuaTable作为全局注册表,定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 public partial class LuaState { public LuaState (int size { globalStack = new LuaStack(size); registry[Constants.GlobalEnvKey] = Factory.NewTable(new LuaTable()); } private LuaStack globalStack; private LuaTable registry = new LuaTable(); public int LoadChunk (byte [] bytes, string chunkName { Chunk chunk = Chunk.Undump(bytes); LoadMainFunc(chunk.MainFunc); return 0 ; } private void LoadMainFunc (FuncPrototype mainFunc ) { Closure c = new Closure(mainFunc); Push(c); if (c.Proto.UpvalueInfos.Length > 0 ) { LuaDataUnion g = registry[Constants.GlobalEnvKey]; c.Upvalues[0 ] = new Upvalue(g); } } }
此外还封装了大量的对LuaStack的操作,如调用函数,设置元表,开启标准库等
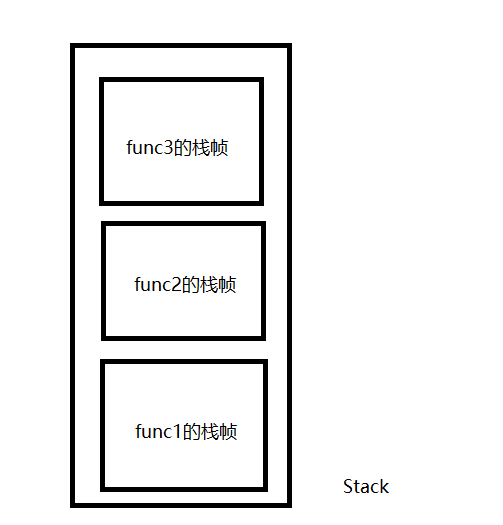
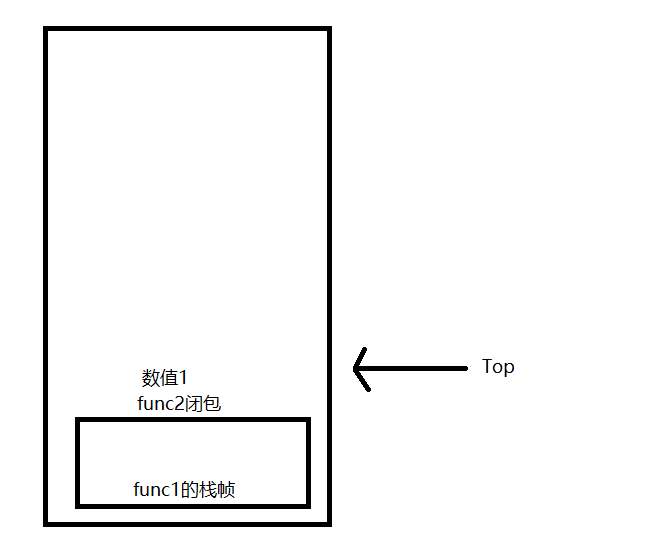
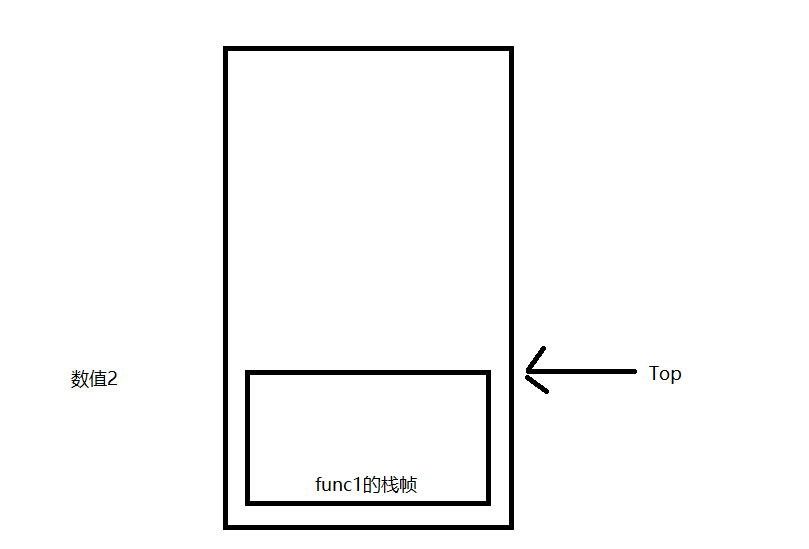
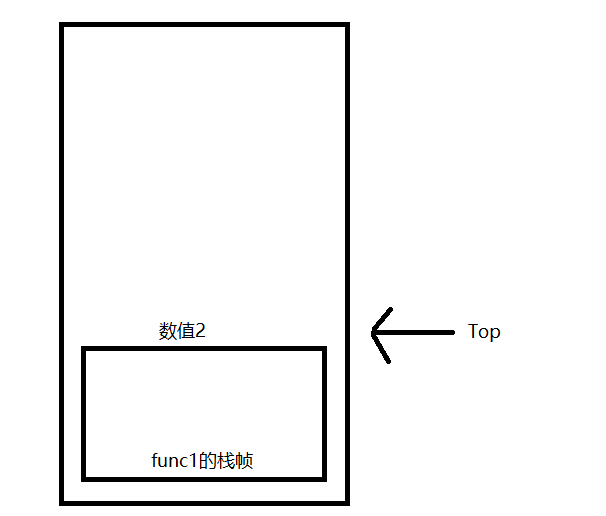
函数调用 函数调用部分可谓是整个CatLua中相当麻烦的一部分,笔者在反复测试重构后,采取了基于栈帧的函数调用流程
所谓栈帧,指的是对栈的一部分切片的抽象 ,每次函数调用都会产生一个栈帧来处理此函数中对栈数据的操作
1 2 3 4 5 6 7 8 9 10 11 12 local func1 = function() func2() end local func2 = function() func3() end local func3 = function() end func1()
同时,在调用函数时还会区分主调栈帧和被调栈帧,比如在func1中调用func2时,func1的栈帧就是主调栈帧,func2的栈帧就是被调栈帧
栈帧的定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 public class FuncCallFrame { public FuncCallFrame (Closure closure = null , int bottom = 0 ) { Closure = closure; Bottom = bottom; int size = 0 ; if (Closure != null && Closure.Proto != null ) { size = Closure.Proto.MaxStackSize; } ReserveRegisterMaxIndex = (Bottom - 1 ) + size; } public LuaDataUnion[] VarArgs; public int PC; public FuncCallFrame Prev; public Closure Closure { get ; private set ; } public int ReserveRegisterMaxIndex { get ; private set ; } public int Bottom { get ; private set ; } }
因为一个LuaState只有一个全局的LuaStack,因为每个栈帧就需要记录下当前栈帧的栈底,方便弹出栈帧时正确恢复栈顶,同时还要记录下前一个函数调用栈帧,方便进行恢复操作
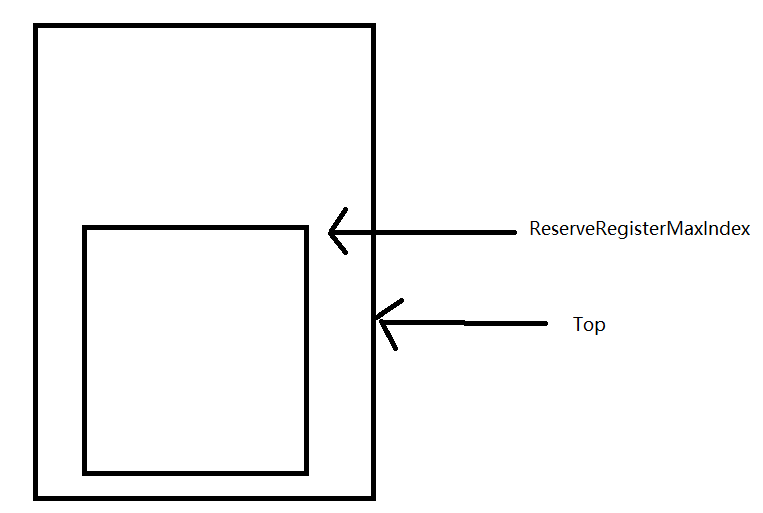
此外还需要注意的是ReserveRegisterMaxIndex这个值,每个栈帧都有N个为寄存器预留的位置,因此在压入新栈帧时就不能占用这些预留的位置
同时可能该栈帧因为操作的数据过多导致栈顶范围溢出了ReserveRegisterMaxIndex,所以在压入新栈帧时也不能占用这些溢出的位置
在考虑上面两个限制后,就需要通过Max(ReserveRegisterMaxIndex + 1,Top +1)来计算出新栈帧的栈底位置,然后调整栈顶到新栈帧的栈底(保证后续压入的函数参数从新栈帧的Bottom开始)
以Lua函数调用为例(C#函数调用流程则是Lua函数调用流程的简化版本),在CatLua中将整个调用流程分为了3个阶段:
调用Lua函数前 执行Lua函数调用 Lua函数调用后
1 2 3 PreLuaFuncCall(argsNum); ExcuteLuaFuncCall(); PostLuaFuncCall(resultNum);
其中argsNum为调用函数的参数数量,resultNum为返回值数量
接下来会以下述代码中func1调用func2的流程来进行讲解
1 2 3 4 5 6 7 8 9 local function func1 () func2(1 ) } local function func2 (num) return 2 } func1()
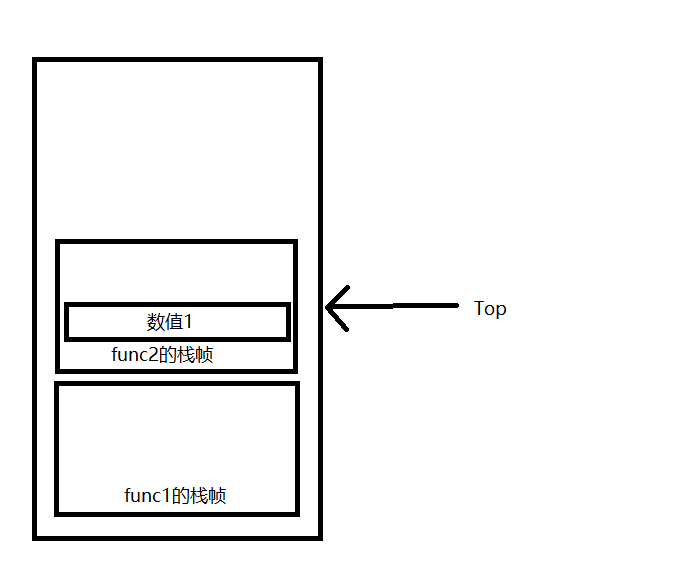
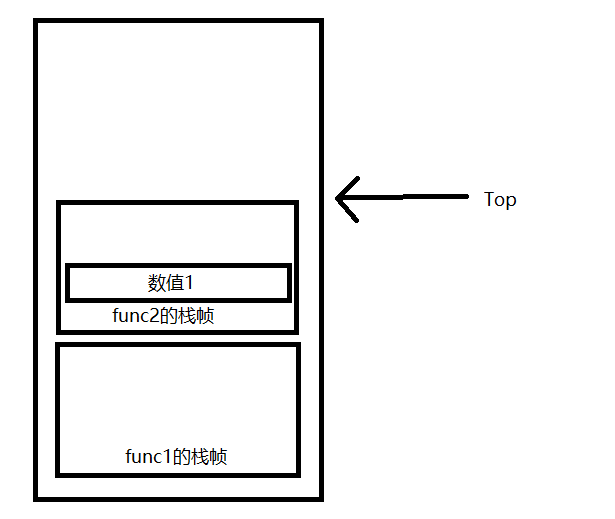
PreLuaFuncCall 在PreLuaFuncCall前,会先将要调用的函数和参数从指定位置复制并压入到主调栈帧的栈顶,并根据Call指令的指令参数和栈顶位置计算出函数参数的数量(如果有变长参数,那么实际参数数量也是在此时被计算出)
进入PreLuaFuncCal后,要从主调栈帧的栈顶弹出函数与参数,并为被调函数创建新栈帧,压入新栈帧和参数
接下来再次修改Top,将其指向ReserveRegisterMaxIndex后的位置,保证后续压入新值不会占用预留的寄存器
接下来如果还有变长参数,就会将变长参数收集到栈帧中
PreLuaFuncCall完整代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 private void PreLuaFuncCall (int argsNum{ LuaDataUnion[] FuncAndParams = globalStack.PopN(argsNum + 1 ); Closure c = FuncAndParams[0 ].Closure; int paramsNum = c.Proto.NumParams; bool isVarArg = c.Proto.IsVararg != 0 ; int bottom = Math.Max(curFrame.ReserveRegisterMaxIndex + 1 , Top + 1 ); FuncCallFrame newFrame = new FuncCallFrame(c,bottom); PushFuncCallFrameAndSetTop(newFrame); globalStack.PushN(FuncAndParams, 1 , paramsNum); SetTop(newFrame.ReserveRegisterMaxIndex); if (argsNum > paramsNum && isVarArg) { LuaDataUnion[] varArgs = new LuaDataUnion[argsNum - paramsNum]; Array.Copy(FuncAndParams, paramsNum + 1 , varArgs, 0 , varArgs.Length); newFrame.VarArgs = varArgs; } }
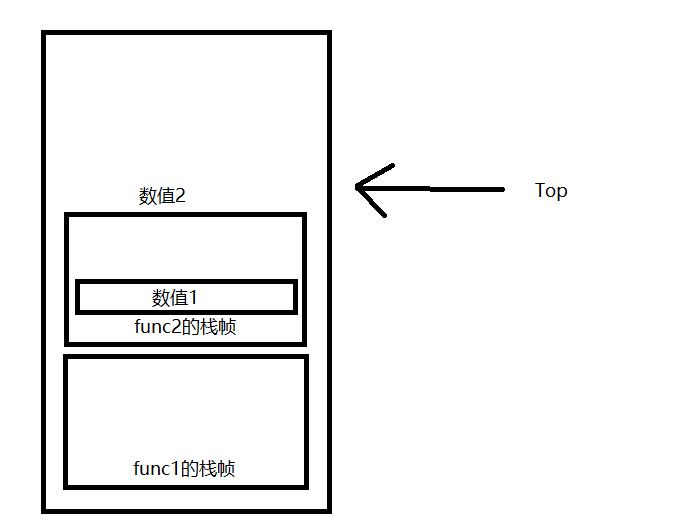
ExcuteLuaFuncCall 执行函数调用部分处理,就是通过一个while true循环不断取出指令执行,然后在碰到Return指令的时候结束循环就可以了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 private void ExcuteLuaFuncCall ( { while (true ) { Instructoin i = new Instructoin(Fetch()); i.Execute(this ); if (i.OpType == OpCodeType.Return) { break ; } } }
需要注意的是,在处理Return指令的时候,会将返回值都压入栈顶,并记录返回值数量(如果有变长返回值,那么实际返回值数量也是在此时被计算出并记录)
PostLuaFuncCall 函数调用结束后,所有返回值都被Return指令放到了栈顶,那么接下来就需要取出返回值,恢复栈顶到Buttom-1,弹出被调栈帧,闭合Upvalue
最后将resultNum个返回值压入到主调栈帧上,不足的部分用nil补齐即可
如此便完成了整个函数调用流程
PostLuaFuncCall完整代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 private void PostLuaFuncCall (int resultNum{ if (resultNum == 0 ) { PopFuncCallFrameAndSetTop(); return ; } LuaDataUnion[] results = globalStack.PopN(CallFrameReturnResultNum); PopFuncCallFrameAndSetTop(); globalStack.PushN(results, 0 , resultNum); }
PCall Lua中的PCall相当于其他语言中的try catch的作用,能够在调用一个函数报错后中断调用流程并将异常信息返回
因此可以直接在C#中使用try catch来实现PCall,并且有了栈帧的概念下,只要在调用前记录下当前栈帧,如果进入了catch块就不断弹出栈帧,直到回到了初始的调用栈帧,最后将异常信息压入栈顶即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public FuncCallState PCall (int argsNum,int resultsNum,int msg { FuncCallFrame frame = curFrame; try { CallFunc(argsNum, resultsNum); } catch (Exception e) { while (curFrame != frame) { PopFuncCallFrameAndSetTop(); } CallFrameReturnResultNum = 1 ; Push(e.Message); return FuncCallState.ErrRun; } return FuncCallState.Ok; }
GC算法 因为C#是自带GC的语言,所以并未给CatLua实现一套GC算法
不过在这里仍然简单阐述下原版Lua的GC算法
双色标记 Lua和C#一样,采用的是引用追踪式GC,每次GC时会从根对象出发(全局变量,栈,寄存器)遍历所有对象,被标记的就是可达对象,否则是不可达的,不可达对象被视为内存垃圾
5.0前采用双色标记 ,每个对象非黑即白(扫描过的是黑色,未扫描过的是白色)
双色标记GC算法过程:
初始化阶段:遍历root引用的对象,将其加入对象链表
标记阶段:从对象链表中取出未扫描元素,将其标记为黑色,并遍历该元素关联的所有对象,也标记为黑色
回收阶段:遍历所有对象,如果是白色就回收,如果是黑色不回收
这种方法要求一次性完成GC不能打断 ,会造成较长时间的卡顿
为什么不能被打断?
因为在标记阶段后创建的新对象在本轮GC中将无法继续被标记,这样就会导致可能会用到的新对象被GC清理掉了从而导致出Bug
三色标记 Lua5.1开始采用三色标记法,实现了增量的回收,3种颜色分别是:
白色 :待访问状态,对象未被GC访问过,如果在结束GC扫描后仍然是白色,就说明其是内存垃圾
灰色 :待扫描状态,对象未被GC访问过,但已经准备进行访问
黑色 :已扫描状态,对象已被GC访问过
三色标记GC算法过程:
初始化阶段,遍历root引用的对象,从白色改为灰色,放入灰色节点链表(灰色节点链表相当于记录了当前GC的进度)
标记阶段:不断从灰色链表取出元素,标记为黑色,然后遍历其关联的所有对象,标记为灰色,加入灰色链表,此阶段可打断
原子标记阶段:不可打断的阶段,用于处理第二灰色链表的标记
回收阶段:灰色链表为空后,遍历所有对象,如果为白色就回收
虽然多数对象是从白到灰,但是像string这种不可能引用其他对象的数据类型是直接从白到黑的
但即便是增量回收,在回收前依然有一个不可打断的原子标记阶段 存在:
首先,因为标记阶段可以被打断,这样在期间可能会有新对象创建,并且被一个黑色对象引用了,但这是不允许的,因为黑色已经标记过了,本轮GC不会再扫描它,这样其引用的的白色对象也不会被标记,到了回收阶段就会被误回收
这时就需要两种不同的处理:
前向barrier :将新创建的对象直接设置为灰色,适用于引用新对象的黑色对象不会频繁改变引用关系的数据类型,如lua的proto后向barrier :将引用新对象的黑色对象设置为灰色,放入第二灰色链表,在原子标记阶段一次性进行标记,适用于黑色对象可能频繁改变引用关系的数据类型,如table。而如果直接把从黑色变灰色的table对象放入灰色链表,因为table的key和value引用关系变化频繁,就可能在黑色和灰色间反复横跳,进行很多重复的扫描,所以需要将table放入第二灰色链表中,在原子标记阶段一次性处理完
词法分析 词法分析所做的即是不断地将源代码字符串中的词法单元 (Token)给识别出来,形成一个Token流供语法分析进行提取
Lua中的Token主要分为以下几类:
分隔符 运算符 字符串字面量 数字字面量 标识符 关键字
CatLua中对词法分析的实现比较简单,通过对首字符的内容switch case加上正则表达式进行Token识别
例如:当前字符指向一个”=”,此字符可能构成了“=”,也可能构成了”==”,那么就判断剩余字符是否以”==”开头,若是,则返回token为”==”,否则返回”=”
具体代码如下:
首先定义TokenType枚举
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 public enum TokenType { Eof, Vararg, SepSemi, SepComma, SepDot, SepColon, SepLable, SepLparen, SepRparen, SepLbrack, SepRbrack, SepLcurly, SepRcurly, OpAsssign, OpMinus, OpWave, OpAdd, OpMul, OpDiv, OpIDiv, OpPow, OpMod, OpBAnd, OpBOr, OpShR, OpShL, OpConcat, OpLt, OpLe, OpGt, OpGe, OpEq, OpNe, OpLen, OpAnd, OpOr, OpNot, KwBreak, KwDo, KwElse, KwElseif, KwEnd, KwFalse, KwFor, KwFunction, KwGoto, KwIf, KwIn, KwLocal, KwNil, KwRepeat, KwReturn, KwThen, KwTrue, KwUntil, KwWhile, Identifier, Number, String, OpUnm = OpMinus, OpSub = OpMinus, OpBNot = OpWave, OpBXor = OpWave, }
然后定义词法分析器Lexer
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 public class Lexer { public Lexer (string chunk, string chunkName { this .chunk = chunk; this .chunkName = chunkName; Line = 1 ; curIndex = 0 ; } private static Regex numberRegex = new Regex(@"^-?\d+$|^(-?\d+)(\.\d+)?" , RegexOptions.Compiled); private static Regex identifierRegex = new Regex(@"^[_\d\w]+" , RegexOptions.Compiled); private static Regex shortStrRegex = new Regex("^\"[^\"]*\"" , RegexOptions.Compiled); private string chunk; private string chunkName; private int curIndex; public void GetNextToken (out int line, out string token, out TokenType type { SkipWhiteSpaces(); line = Line; token = default ; type = default ; if (curIndex >= chunk.Length) { type = TokenType.Eof; token = "Eof" ; return ; } char c = chunk[curIndex]; switch (c) { case ';' : Next(1 ); type = TokenType.SepSemi; token = ";" ; return ; case ',' : Next(1 ); type = TokenType.SepComma; token = "," ; return ; case '(' : Next(1 ); type = TokenType.SepLparen; token = "(" ; return ; case ')' : Next(1 ); type = TokenType.SepRparen; token = ")" ; return ; case '=' : if (Test("==" )) { Next(2 ); type = TokenType.OpEq; token = "==" ; } else { Next(1 ); type = TokenType.OpAsssign; token = "=" ; } return ; } if (c == '.' || char .IsDigit(c)) { token = ScanNumber(); type = TokenType.Number; return ; } if (c == '_' || char .IsLetter(c)) { token = ScanIdentifier(); if (KeyWordTokenMap.TryGetValue(token,out type)) { return ; } type = TokenType.Identifier; return ; } Error("语法错误,当前字符为:" + c); } private void Next (int n { curIndex += n; } private bool Test (string s { return chunk.Substring(curIndex).StartsWith(s); } }
这样就完成了词法分析的过程
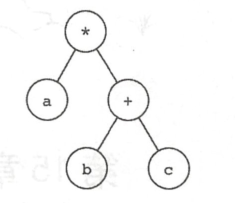
语法分析 语法分析的作用即是根据编程语言的文法规则,将token序列转换为抽象语法树(AST)
如a * ( b + c )的AST如下:
Lua的文法规则采用了一种上下文无关文法EBNF(扩展的巴科斯范式)
该文法定义了编程语言中每种合法语句/表达式由一些什么东西构成
语句和表达式的区别主要在于:语句可执行,表达式可求值 (因此函数即是表达式也是语句)
同时Lua采用的是递归下降 法进行语法分析,遇到关键字就检查是否匹配,遇到语句/表达式就调用相应的解析方法进行解析
一个示例:解析do语句 do语句在Lua中表现为:
do语句的EBNF文法定义为:
该定义表达了Lua中的do语句由1个关键字do,1个代码块block,最后再来1个关键字End构成
而在进行具体的do语句解析中,逻辑就是这样的:
提取并丢弃do关键字 ParseBlock解析1个block对象 提取并丢弃end关键字 用block对象创建Dostat对象中并返回
解析do语句的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 private static DoStat ParseDoStat (Lexer lexer ){ lexer.GetNextTokenOfType(TokenType.KwDo, out _, out _); Block block = ParseBlock(lexer); lexer.GetNextTokenOfType(TokenType.KwEnd, out _, out _); return new DoStat(block); }
函数原型编译 在得到了AST后,就需要根据这个AST生成函数原型
编译过程和语法分析过程类似,也是采取一种递归下降 的方法,根据遇到的语句/表达式调用不同的编译方法生成对应的指令
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 private static void CompileStat (GenFuncInfo fi, BaseStat stat ) { if (stat is FuncCallStat) { CompileFuncCallStat(fi, (FuncCallStat)stat); return ; } if (stat is BreakStat) { CompileBreakStat(fi, (BreakStat)stat); return ; } if (stat is DoStat) { CompileDoStat(fi, (DoStat)stat); return ; } throw new Exception("不支持编译的语句:" + stat.GetType()); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 private static void CompileExp (GenFuncInfo fi, BaseExp exp, int reg, int num ) { if (exp is NilExp) { int b = reg + num - 1 ; fi.EmitLoadNil(reg, b); return ; } if (exp is FalseExp) { fi.EmitLoadBool(reg, 0 , 0 ); return ; } if (exp is TrueExp) { fi.EmitLoadBool(reg, 1 , 0 ); return ; } throw new Exception("不支持编译的表达式:" + exp.GetType()); }
当然这里只是简要的展示了一下编译流程,实际过程中是有非常多的细节要处理的,包括但不限于:
计算寄存器位置 作用域层级管理 处理变长参数 处理变长返回值 处理Upvalue 处理跳转类指令的参数回填